A simple guide to web scraping using BeautifulSoup and requests
Image by Muzammil Hussain by Canva

As a beginner in AI and ML with Python, I needed to collect a lot of images to train my model. My model was designed to perform a certain task based on the visual data. I started by using a Chrome extension called “Image Downloader” to scrape images from the web. It was a tedious and time-consuming process, but I didn’t know any better. I managed to get about 4500 images in one day, but I was constantly looking for a faster and more automated way to gather data.
I discovered web scraping techniques that could make my data collection much easier and faster. I was excited to learn how to automate my tasks and extract data from web pages. I studied Selenium, a tool that can simulate browser actions, and BeautifulSoap4, a library that can parse and manipulate HTML data. In this article, we will start with the basics of BS4 scraping.
Understanding Web Scraping
Before we get into the details, let’s see what web scraping is and how it can benefit us. Web scraping is a technique that allows us to automatically collect data from websites. It enables us to access various types of information like text, images, tables, and more, which can be useful for purposes like data analysis, market research, or building datasets for machine learning.
Installing Python and Required Libraries
We will use Python for this project, so make sure you have Python on your system. If you don’t, you can download and install it from python.org. We will also use two of the most popular libraries for web scraping.
- Requests: This allows us to send HTTP requests and retrieve web pages.
- Beautiful Soup: It helps us to parse and extract data from HTML or XML documents.
To install these libraries, we’ll have to open our command prompt or terminal and run the following commands:
$ pip install requests
$ pip install beautifulsoup4Writing code to scrape data
So, by today, we will scrape images from Puma’s website and save them to our local directory. To begin with, we need to import some libraries that we will use throughout the process.
import requests
from bs4 import BeautifulSoupAs we have imported our important libraries, it’s time to make our first get request using requests library.
# sending a get request
url = 'https://us.puma.com/us/en/men/shoes?offset=576'
response = requests.get(url)So, from the above code, we can see that we have a response of 200.
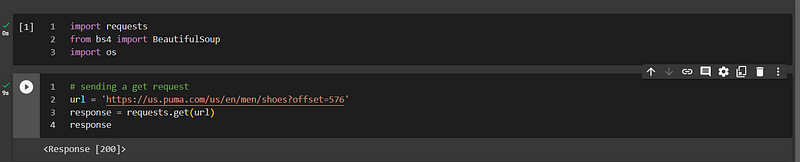
We have confirmed that our request was successful by checking the response status code. To view the HTML content of the response, we can use response.content and see the HTML code of the webpage.
Now that we have the HTML content, we can use Beautiful Soup to extract the data we want from the HTML tags or the CSS selectors. To find the CSS selector of a specific element, we can use the browser’s inspect tool, which we can open by pressing CTRL + SHIFT + C
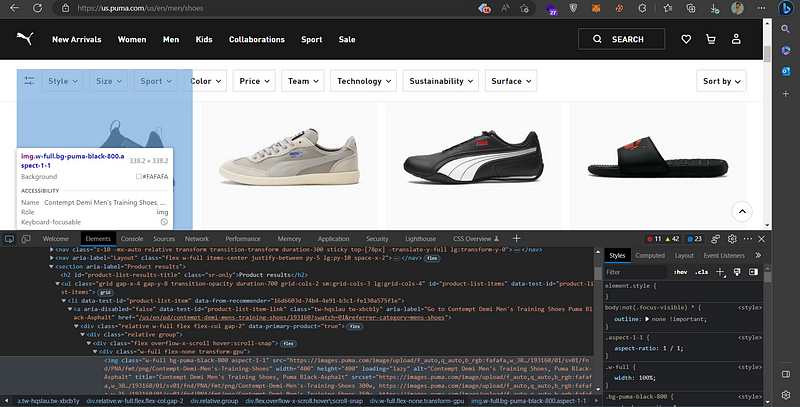
After finding the tag that contains the data we want to scrape, we can right-click on it and choose the option to copy the CSS selector.

Now that we have the selector of the element we want to scrape, we can use BeautifulSoup to find the corresponding tags in the HTML content.
soup = BeautifulSoup(response.content, 'html.parser')
img_tags = soup.select('#product-list-items > li:nth-child(1) > a > div > div:nth-child(1) > div > div:nth-child(1) > img')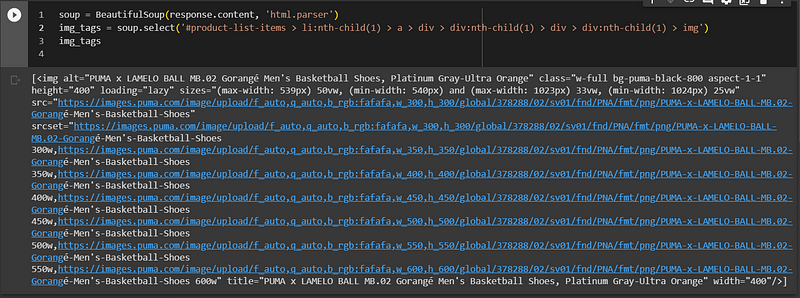
Since we want to get all the sneaker images, we can modify our selector to be more general. The img_tags variable will contain an array of img tags. Our new selector will be div > div:nth-child(1) > img and our new img_tags variable will look like this.
img_tags = soup.select('div > div:nth-child(1) > img')
We have extracted all the img tags that contain the sneakers we want to scrape. The next step is to get the source URL of each image from the src attribute of the img tags. We can use a for loop to iterate over the img tags and get their URLs one by one
for snkr in img_tags:
img_url = snkr['src']
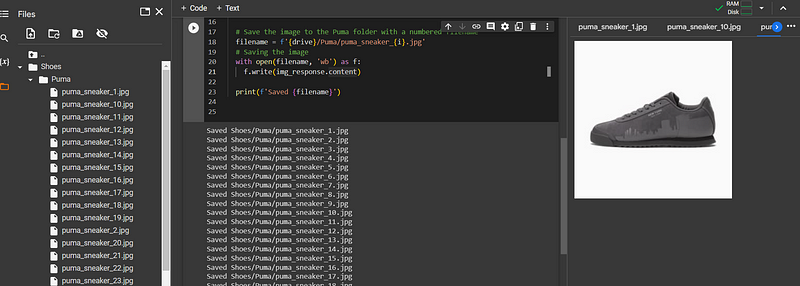
We have obtained the source URLs of the sneakers we want to scrape. The next step is to download their images and save them to our local directory. Here is the final code for our scrapper that will dynamically create a new folder and save the images into it.
By executing the code above, we have successfully scraped and saved the images to our local directory.
Handling Pagination and Dynamic Content
Web scraping can become more complex when the data we need is not on a single page or is hidden behind some dynamic features. In these cases, we need to use some advanced techniques to access the data. For example, we can use loops to navigate through multiple pages and scrape the data from each one. Alternatively, we can use libraries like Selenium or browser developer tools to interact with dynamic elements and capture network requests.
Conclusion
Today, we have learned how to scrape any website in minutes with Python using requests and the BeautifulSoup libraries. We have seen how to send requests to websites, parse HTML content, and extract data using CSS selectors. Web scraping is a useful skill that can help us collect valuable data from various sources on the web.
However, web scraping can also be challenging when the websites we want to scrape have dynamic or interactive features that require us to use additional tools or techniques. In the next article, we will explore how to scrape dynamic websites using Selenium. Stay tuned for more web scraping tutorials!